Creating a Face Multitask Dataset
Table of Contents
Overview
With current 3D animation software, you no longer need large studio resources to create your own short films. Current hardware and software can make real-time animation possible as seen with the popularity of V-tubers. As it’s easier to create, motion capture should be making its way to the bedroom creator. I’m interested in where deep learning can help with this. Focusing on the V-tuber aspect, facial capture seems to be a strong starting point, especially when there are models for different aspects of facial capture like head pose and facial landmarks. However, these models were trained separately. I am interested in seeing if we can further optimize for different related facial motion capture tasks in a deep learning approach. But before I can train, I need a dataset.
Dataset
It’s costly to label a dataset myself, so I started from the YouTube Faces DB. More specifically, I used a processed Kaggle dataset as the real starting point to get many frames containing face detections with facial keypoints. I further add other outputs like head pose and gaze vector estimation, adapting an OpenVINO-based gaze detection code.
Some frames failed in adding the data labels we want, but we just drop them. We still have a sizeable dataset to work with (16 GB zipped).
Format
The data itself are .npz files. Each npz file contains numpy arrays for a single video. Once loaded using numpy, the npz object contains the following objects:
| Field name in npz object | Description |
|---|---|
| colorImages | the rgb frames for given video |
| boundingBox | the x-y coordinates of each corner a bounding box for the detected face |
| landmarks2D | the 2D 68 facial landmarks for each frame |
| landmarks3D | the 3D 68 facial landmarks for each frame; the x-y coordinates match the 2D |
| headPose | 3-dimensional head pose angles in format of [yaw, pitch, roll] |
| gazeVector | 3-dimensional vector estimating gaze direction in format of [x, y, z] |
Dataloader
Now that we have data and I’m intending to use pytorch, we can make use of pytorch’s dataset class to feed data in my future training code. In the dataloader, we also intend to get more out of our data by adding augmentations. Also, with a subset of our data being affected when we apply spatial augmentations (rotations, shifts, etc.), I had to account for the changes, particularly with the landmarks. If we apply a horizontal flip, the landmarks not only change x-y coordinates but also swap (the x-y coordinates for left eye landmarks are now right eye landmarks).
In all, our transforms to the image is as follows: input -> color jitter -> grayscale -> Random bounding box crop augmentations -> random rotation and shift -> resize to 128x128
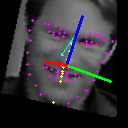

The code for this dataloader can be found here.
Next steps
Now, we have a face dataset containing all the labels we want to train on and code to load with augmentations. One thing to note is that we’re using other models to get the labels, and we haven’t gone through the data manually to clean it.